点评专家 | | 赵兴明 (复旦大学 ) | 薛宇 (华中科技大学)
RNA 亚细胞定位与其生成、加工和功能密切相关 [1, ,因此,解析 RNA 的亚细胞定位对其功能研究至关重要。利用传统的实验生物学方法,如 FISH 和细胞组分分离后鉴定等可以有效地发现目的 RNA 的亚细胞定位,但是其通量较低、且不同实验方法的特异性也会导致某些 RNA 无法被准确定位。近期,结合亚细胞 RNA 组分分离和后续高通量测序分析,大量的 RNA 亚细胞定位信息被报道,利用这些数据并结合机器学习和深度学习的方法,也实现了对 RNA 亚细胞定位的预测,但是已有的预测方法仅局限于单一类型的 RNA 分子,并且模型可解释性较差,未能提供影响 RNA 亚细胞定位的关键序列信息。
2022 年12 月3 日,复旦大学生物医学研究院杨力研究组在Briefings in Bioinformatics “RNAlight: a machine learning model 的研究论文。该研究首先基于LightGBM 框架开发了机器学习模型——RNAlight 用于预测多类型RNA 的亚细胞定位,通过整合Tree 及序列组装算法,RNAlight 能有效地鉴定影响RNA 亚细胞定位的关键核苷酸序列特征,并用于不同类型RNA 的亚细胞定位预测分析。中国科学院上海营养与健康研究所(原中科院– 德国马普学会计算生物学伙伴研究所)博士研究生袁国华和博士后王滢为本文共同第一作者,复旦大学生物医学研究院杨力研究员为本文通讯作者,中国科学院上海营养与健康研究所王光中研究员也参与了该项研究。
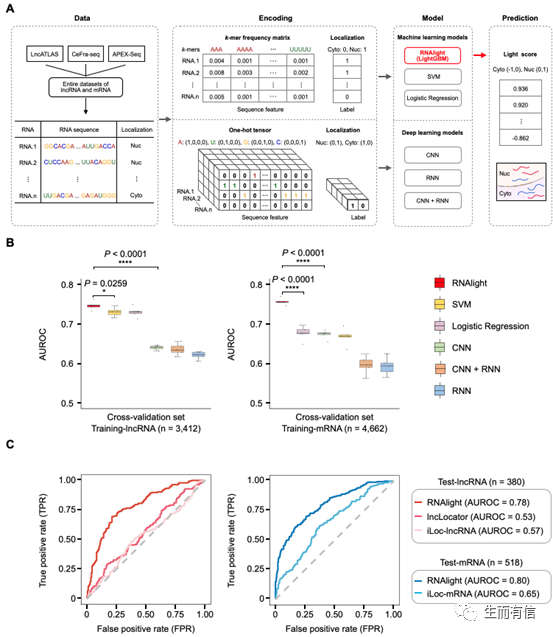
为寻找到最优的RNA亚细胞定位预测流程,科研人员首先构建了一系列机器学习模型和深度学习模型开展lncRNA和mRNA的亚细胞定位分析。其中,基于LightGBM(Light Gradient Boosting Machine)[3]框架的机器学习模型——RNAlight,表现出最好的预测效果,并优于其它已报道的RNA亚细胞定位预测模型。
RNAlight表现出最优的RNA亚细胞定位预测性能
利用RNAlight鉴定与RNA亚细胞定位相关的RNA序列特征及RNA结合蛋 白
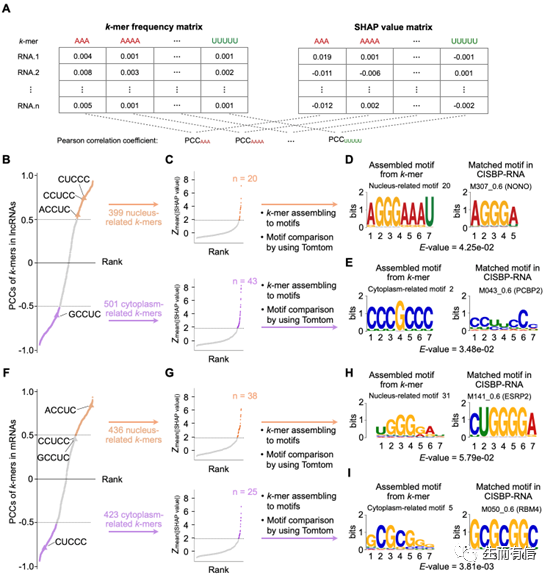
Tree SHAP(SHapley Additive exPlanations)[4]算法可以通过计算输入特征的Shapley value来量化其对模型输出的贡献程度。在本工作中,科研人员将Tree SHAP算法整合到RNAlight中,借此鉴定出了与RNA亚细胞定位相关的RNA序列特征。进一步地,科研人员通过序列组装(k-mer assembly)算法将这些RNA序列特征组装为共有序列(consensus sequence),并与已知的RNA结合蛋白相关基序进行比对,寻找到了参与调控RNA亚细胞定位的RNA结合蛋白。
RNAlig ht 可以鉴定出与RNA 亚细胞定位相关的序列特征及RB P
利用RNAlight预测多类型RNA亚细胞定位模式
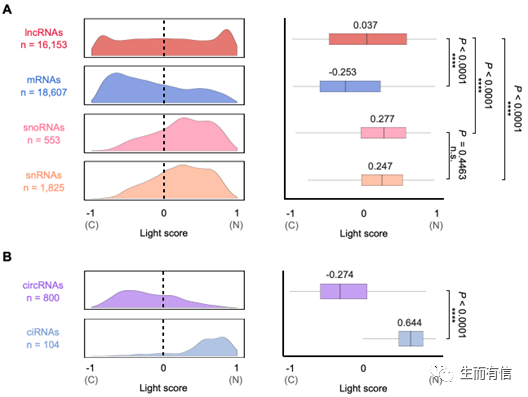
该研究还应用RNAlight预测了其它类型的RNA亚细胞定位,包括核小RNA(small nuclear RNA,snRNA)、核仁小RNA(small nucleolar RNA,snoRNA)和两种产生机制不同、定位不同的环形RNA(circular RNA),RNAlight准确地预测出了上述类型RNA的亚细胞定位模式,提示RNAlight能够学习并鉴定出影响RNA亚细胞定位的普适性序列特征。
解析RNA的亚细胞定位有助于我们更加深入地探究其生物学功能。本项目开发的RNAlight工具可以完成多类型RNA亚细胞定位预测及核苷酸序列特征鉴定,为RNA亚细胞定位及功能研究提供了新的思路和方法。 该工作获得了国家自然科学基金委、科技部国家重点研发计划、中国博士后科学基金会、上海超级博士后激励计划等项目资助。 原文链接: https://doi.org/10.1093/bib/bbac509
专 家 点 评 :
一级序列组成决定了分子的结构和功能,一级分子序列包含丰富信息的同时,其简单的字母组成及其复杂的内在非线性规律,使得基因组生命天书的解读难上加难。为此,在生物信息学的最初发展阶段,已经开发了各种各样的算法来解读生物序列中的内在信息,其中一个最为广泛的应用就是预测蛋白质的亚细胞位置。2010年以后,蛋白质亚细胞定位已经研究非常成熟,相关的研究工作也逐渐变少。同时,伴随着基因测序技术的飞速发展和测序价格的下降,越来越多的研究关注到基因组和转录组。相应的,越来越多种类的RNA分子被鉴定出来。人们越来越认识到,除了传统的mRNA外,还有miRNA、lncRNA、circular RNA等各种RNA分子,并且这些RNA在各种生物过程中起着重要的作用,但是我们对RNA的生物功能了解尚少。在细胞中,RNA的亚细胞位置对于理解RNA的合成与功能有着重要的意义。
最近,生物信息学领域的领军学者、复旦大学生物医学研究院的杨力研究员开发了一种新型机器学习模型——RNAlight,能够准确预测RNA的亚细胞位置,为理解RNA的功能提供了基础。相比其他方法,该模型具有以下亮点:(1)可以自动学习序列中的重要特征,这些特征决定了RNA的亚细胞位置,同时这些序列特征有助于理解RNA的亚细胞定位机制;(2)相比已有方法,该算法具有更好的普适性,可应用于不同类型的RNA分子,包括mRNA、lncRNA、circular RNA等;(3)该模型简单优美,没有采用复杂华丽的深度神经网络,简单且可解释的生物特征大大加强了模型的可解释性。 RNA研究是最近兴起的热门研究领域,相信杨力研究员的工作能够启发更多的AI+RNA研究工作出现。特别是在最近大语言模型火热的背景下,相信机器学习与人工智能能够在RNA领域大放异彩。
基于序列的生物大分子的细胞亚定位预测,是生物信息学领域经典的机器学习应用场景。2001年,清华大学孙之荣教授等人首次将机器学习技术“支持向量机”应用于蛋白质序列与结构分析,建立了基于序列特征的蛋白质细胞亚定位预测算法SubLoc。该工作所体现的机器学习的力量和优雅,深刻地影响了整整一代的中国青年生信研究者。 过去,细胞亚定位预测主要集中在蛋白质上,RNA的细胞亚定位的相关预测工作较少。近期,非编码RNA信息学领域的领军学者、复旦大学生物医学研究院杨力教授研究组,从RNA序列中提取“k-mer”特征,利用集成学习技术LightGBM,构建了预测mRNA和lncRNA细胞亚定位的RNAlight算法。文章的主要亮点有:1)k-mer即生物序列中长度为k的字符串,国际上最早由中国生物信息学领域的奠基人之一、同为复旦大学的郝柏林院士应用到生物序列分析中。本工作使用k-mer,既因其在表征生物序列特征方面的重要性,亦有怀念领域前辈之意;2)集成学习的原理,即集合多个弱分类器从而获得较高的预测准确性,通俗来讲就是“一群臭皮匠,完爆诸葛亮”。本文通过比较,发现集成学习在本工作的应用场景里,性能比经典机器学习也就是支持向量机和深度学习好。选择支持向量机,自然是致敬孙之荣教授的开创性工作;3)首次将基因组分析里的研究策略应用到细胞亚定位预测的结果分析里,例如文章原文中图3的motif分析,有同济大学张勇教授在ChIP-Seq数据分析的影子,图4里各类RNA细胞亚定位的趋势分析,则是典型基因组分析的路数。因此,本工作为序列分析提供了新的研究策略、新视角;4)当代机器学习的逻辑是“大力出奇迹”,而杨力研究员的研究风格则素来以优雅、细腻著称,本工作中的预测部分基本上是简单、粗暴的路数,后续的分析又严密、扎实,一言以蔽之:优雅地挥着大锤。 最后,本工作吹响了RNA细胞亚定位预测的号角。未来可以做的工作很多,例如,RNAlight考虑定长的k-mer,未来是否可以用自然语言处理技术如BERT等来提取不定长k-mer的特征?除了k-mer,融合其它类型的序列、结构特征是否能够提高准确性?采用预训练的策略,从海量RNA序列中学习相似性,再迁移到亚定位预测的场景里,是否能提高预测的泛化性能?
1. Mili S, Macara IG. RNA localization and polarity: from A(PC) to Z(BP), Trends Cell Biol 2009;19:156-164.
2. Chen LL. Towards higher-resolution and in vivo understanding of lncRNA biogenesis and function, Nat Methods 2022;19:1152-1155.
3. Ke GL, Meng Q, Finley T et al. LightGBM: a highly efficient gradient boosting decision tree, Advances in Neural Information Processing Systems 30 (Nips 2017) 2017;30.
4. Lundberg SM, Erion G, Chen H et al. From Local Explanations to Global Understanding with Explainable AI for Trees, Nat Mach Intell 2020;2:56-67.
杨力研究员于中科院上海生科院生物化学与细胞生物学研究所取得博士学位,后分别于美国耶鲁大学、康涅狄格大学健康中心从事博士后研究,2011年加入原中科院-德国马普学会计算生物学伙伴研究所开展独立研究工作,现为复旦大学生物医学研究院特聘研究员。杨力团队致力于非编码RNA及基因组编辑等前沿技术创新体系研究,近5年来主要创建和利用一系列高效计算生物学分析新流程开展大数据分析,围绕外显子环形RNA生成加工和功能作用新机制、高效基因组碱基编辑新体系开发和应用、RNA人工智能生物学等前沿领域开展合作探索,取得了一系列国际领先的重要原创成果。在Cell、Mol Cell、Nat Biotechnol、Genome Biol和Genome Res等学术期刊发表通讯或共同通讯作者研究论文50余篇、并被Cell、、Science和Nat Rev Mol Cell Biol等多次专评;受邀在Cell、Science和Trends Cell Biol 等发表通讯或共同通讯作者综述及专评10余篇;Google scholar引用超过19,000次。研究成果共申请专利10余项,其中3项专利已获授权。曾获上海市“浦江人才”计划、中科院百人计划(终期评估 “优秀”)、中青年科技创新领军人才、万人计划科技创新领军人才、基金委杰出青年基金等;入选Elsevier中国高被引学者(2020、2021)。所培养的研究生多人次获得吴瑞奖学金、中科院院长奖学金、博士研究生国家奖学金和上海市优秀毕业生等,所培养的博士后多人次入选国家“博新计划”和上海市“超级博士后”激励计划。
关于湖北省生物信息学会 :
湖北省生物信息学会,是由湖北省内从事生物信息学科技工作者自愿组成的全省性、学术性、非营利性的社会团体。学会致力于制定生物信息学专业规范,加强学术交流与合作,推动人才培养,促进理事单位及省内外生物信息学产业的健康可持续发展。
文章导航